Text classification is a very classical problem. The goal is to classify documents into a fixed number of predefined categories, given a variable length of text bodies. It is widely use in sentimental analysis (IMDB, YELP reviews classification), stock market sentimental analysis, to GOOGLE’s smart email reply. This is a very active research area both in academia and industry. In the following series of posts, I will try to present a few different approaches and compare their performances. Ultimately, the goal for me is to implement the paper Hierarchical Attention Networks for Document Classification.
Given the limitation of data set I have, all exercises are based on Kaggle’s IMDB dataset. And implementation are all based on Keras.
Text classification using CNN
In this first post, I will look into how to use convolutional neural network to build a classifier, particularly Convolutional Neural Networks for Sentence Classification - Yoo Kim.
First use BeautifulSoup to remove some html tags and remove some unwanted characters.
def clean_str(string):
"""
Tokenization/string cleaning for dataset
Every dataset is lower cased except
"""
string = re.sub(r"\\", "", string)
string = re.sub(r"\'", "", string)
string = re.sub(r"\"", "", string)
return string.strip().lower()
texts = []
labels = []
for idx in range(data_train.review.shape[0]):
text = BeautifulSoup(data_train.review[idx])
texts.append(clean_str(text.get_text().encode('ascii','ignore')))
labels.append(data_train.sentiment[idx])Keras has provide very nice text processing functions.
tokenizer = Tokenizer(nb_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print('Found %s unique tokens.' % len(word_index))
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)For this project, I have used Google Glove 6B vector 100d. For Unknown word, the following code will just randomize its vector.
GLOVE_DIR = "~/data/glove"
embeddings_index = {}
f = open(os.path.join(GLOVE_DIR, 'glove.6B.100d.txt'))
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
f.close()
embedding_matrix = np.random.random((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vectorA simplified Convolutional
First, I will just use a very simple convolutional architecture here. Simply use total 128 filters with size 5 and max pooling of 5 and 35, following the sample from this blog
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
l_cov1= Conv1D(128, 5, activation='relu')(embedded_sequences)
l_pool1 = MaxPooling1D(5)(l_cov1)
l_cov2 = Conv1D(128, 5, activation='relu')(l_pool1)
l_pool2 = MaxPooling1D(5)(l_cov2)
l_cov3 = Conv1D(128, 5, activation='relu')(l_pool2)
l_pool3 = MaxPooling1D(35)(l_cov3) # global max pooling
l_flat = Flatten()(l_pool3)
l_dense = Dense(128, activation='relu')(l_flat)
preds = Dense(2, activation='softmax')
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_1 (InputLayer) (None, 1000) 0
____________________________________________________________________________________________________
embedding_1 (Embedding) (None, 1000, 100) 8057000 input_1[0][0]
____________________________________________________________________________________________________
convolution1d_1 (Convolution1D) (None, 996, 128) 64128 embedding_1[0][0]
____________________________________________________________________________________________________
maxpooling1d_1 (MaxPooling1D) (None, 199, 128) 0 convolution1d_1[0][0]
____________________________________________________________________________________________________
convolution1d_2 (Convolution1D) (None, 195, 128) 82048 maxpooling1d_1[0][0]
____________________________________________________________________________________________________
maxpooling1d_2 (MaxPooling1D) (None, 39, 128) 0 convolution1d_2[0][0]
____________________________________________________________________________________________________
convolution1d_3 (Convolution1D) (None, 35, 128) 82048 maxpooling1d_2[0][0]
____________________________________________________________________________________________________
maxpooling1d_3 (MaxPooling1D) (None, 1, 128) 0 convolution1d_3[0][0]
____________________________________________________________________________________________________
flatten_1 (Flatten) (None, 128) 0 maxpooling1d_3[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 128) 16512 flatten_1[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 258 dense_1[0][0]
====================================================================================================
Total params: 8301994
____________________________________________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 43s - loss: 0.6347 - acc: 0.6329 - val_loss: 0.6107 - val_acc: 0.7024
Epoch 2/10
20000/20000 [==============================] - 43s - loss: 0.4141 - acc: 0.8188 - val_loss: 0.4098 - val_acc: 0.8180
Epoch 3/10
20000/20000 [==============================] - 43s - loss: 0.3252 - acc: 0.8651 - val_loss: 0.4162 - val_acc: 0.8148
Epoch 4/10
20000/20000 [==============================] - 44s - loss: 0.2651 - acc: 0.8929 - val_loss: 0.3545 - val_acc: 0.8640
Epoch 5/10
20000/20000 [==============================] - 43s - loss: 0.2170 - acc: 0.9140 - val_loss: 0.2764 - val_acc: 0.8906
Epoch 6/10
20000/20000 [==============================] - 43s - loss: 0.1666 - acc: 0.9382 - val_loss: 0.4196 - val_acc: 0.8496
Epoch 7/10
20000/20000 [==============================] - 43s - loss: 0.1223 - acc: 0.9568 - val_loss: 0.4271 - val_acc: 0.8680
Epoch 8/10
20000/20000 [==============================] - 43s - loss: 0.0896 - acc: 0.9683 - val_loss: 0.8233 - val_acc: 0.8308
Epoch 9/10
20000/20000 [==============================] - 43s - loss: 0.0830 - acc: 0.9770 - val_loss: 0.5868 - val_acc: 0.8852
Epoch 10/10
20000/20000 [==============================] - 43s - loss: 0.0667 - acc: 0.9794 - val_loss: 0.5159 - val_acc: 0.8872The accuracy we can achieve is 89%
Deeper Convolutional neural network
In Yoon Kim’s paper, multiple filters have been applied. This can be easily implemented using Keras Merge Layer.
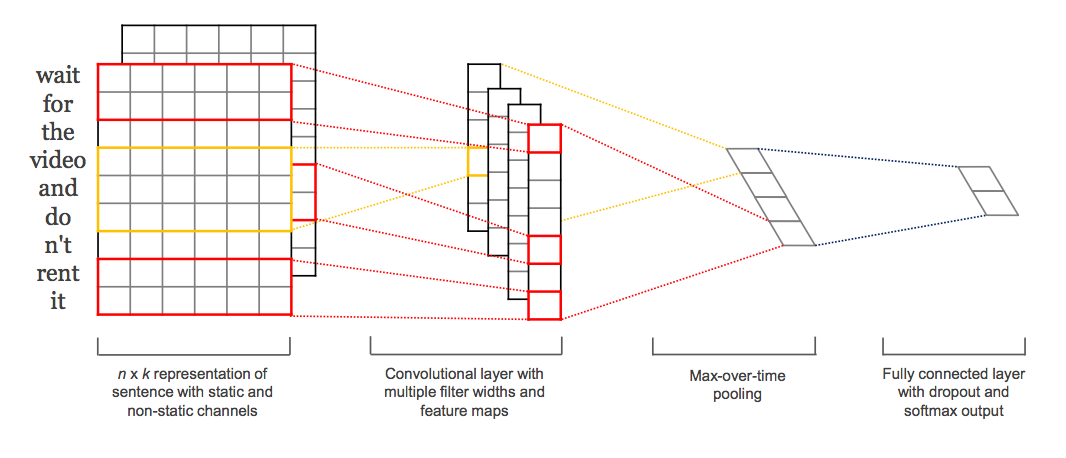 |
convs = []
filter_sizes = [3,4,5]
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
for fsz in filter_sizes:
l_conv = Conv1D(nb_filter=128,filter_length=fsz,activation='relu')(embedded_sequences)
l_pool = MaxPooling1D(5)(l_conv)
convs.append(l_pool)
l_merge = Merge(mode='concat', concat_axis=1)(convs)
l_cov1= Conv1D(128, 5, activation='relu')(l_merge)
l_pool1 = MaxPooling1D(5)(l_cov1)
l_cov2 = Conv1D(128, 5, activation='relu')(l_pool1)
l_pool2 = MaxPooling1D(30)(l_cov2)
l_flat = Flatten()(l_pool2)
l_dense = Dense(128, activation='relu')(l_flat)
preds = Dense(2, activation='softmax')(l_dense)
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_2 (InputLayer) (None, 1000) 0
____________________________________________________________________________________________________
embedding_2 (Embedding) (None, 1000, 100) 8057000 input_2[0][0]
____________________________________________________________________________________________________
convolution1d_4 (Convolution1D) (None, 998, 128) 38528 embedding_2[0][0]
____________________________________________________________________________________________________
convolution1d_5 (Convolution1D) (None, 997, 128) 51328 embedding_2[0][0]
____________________________________________________________________________________________________
convolution1d_6 (Convolution1D) (None, 996, 128) 64128 embedding_2[0][0]
____________________________________________________________________________________________________
maxpooling1d_4 (MaxPooling1D) (None, 199, 128) 0 convolution1d_4[0][0]
____________________________________________________________________________________________________
maxpooling1d_5 (MaxPooling1D) (None, 199, 128) 0 convolution1d_5[0][0]
____________________________________________________________________________________________________
maxpooling1d_6 (MaxPooling1D) (None, 199, 128) 0 convolution1d_6[0][0]
____________________________________________________________________________________________________
merge_1 (Merge) (None, 597, 128) 0 maxpooling1d_4[0][0]
maxpooling1d_5[0][0]
maxpooling1d_6[0][0]
____________________________________________________________________________________________________
convolution1d_7 (Convolution1D) (None, 593, 128) 82048 merge_1[0][0]
____________________________________________________________________________________________________
maxpooling1d_7 (MaxPooling1D) (None, 118, 128) 0 convolution1d_7[0][0]
____________________________________________________________________________________________________
convolution1d_8 (Convolution1D) (None, 114, 128) 82048 maxpooling1d_7[0][0]
____________________________________________________________________________________________________
maxpooling1d_8 (MaxPooling1D) (None, 3, 128) 0 convolution1d_8[0][0]
____________________________________________________________________________________________________
flatten_2 (Flatten) (None, 384) 0 maxpooling1d_8[0][0]
____________________________________________________________________________________________________
dense_3 (Dense) (None, 2) 770 flatten_2[0][0]
====================================================================================================
Total params: 8375850
____________________________________________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 117s - loss: 0.4950 - acc: 0.7472 - val_loss: 0.2895 - val_acc: 0.8830
Epoch 2/10
20000/20000 [==============================] - 117s - loss: 0.2868 - acc: 0.8807 - val_loss: 0.2460 - val_acc: 0.9036
Epoch 3/10
20000/20000 [==============================] - 118s - loss: 0.2040 - acc: 0.9202 - val_loss: 0.2530 - val_acc: 0.8986
Epoch 4/10
20000/20000 [==============================] - 117s - loss: 0.1293 - acc: 0.9530 - val_loss: 0.2931 - val_acc: 0.8870
Epoch 5/10
20000/20000 [==============================] - 117s - loss: 0.0596 - acc: 0.9788 - val_loss: 0.4155 - val_acc: 0.8896
Epoch 6/10
20000/20000 [==============================] - 117s - loss: 0.0334 - acc: 0.9881 - val_loss: 0.5213 - val_acc: 0.8954
Epoch 7/10
20000/20000 [==============================] - 117s - loss: 0.0173 - acc: 0.9934 - val_loss: 0.5742 - val_acc: 0.8910
Epoch 8/10
20000/20000 [==============================] - 118s - loss: 0.0166 - acc: 0.9949 - val_loss: 0.6220 - val_acc: 0.8944
Epoch 9/10
20000/20000 [==============================] - 117s - loss: 0.0114 - acc: 0.9970 - val_loss: 0.6947 - val_acc: 0.8934
Epoch 10/10
20000/20000 [==============================] - 117s - loss: 0.0095 - acc: 0.9967 - val_loss: 0.8724 - val_acc: 0.8974As you can see, the result slighly improved to 90.3%
To achieve the best performances, we can 1) fine tune hyper parameters 2) further improve text preprocessing 3) use drop out layer
Full source code is in my repository in github.
Conclusion
Based on the observation, the complexity of convolutional neural network doesn’t seem to improve performance, at least using this small dataset. We might be able to see performance improvement using larger dataset, which I won’t be able to verify here. One observation I have is allowing the embedding layer training or not does significantly impact the performance, same did pretrained Google Glove word vectors. In both cases, I can see performance improved from 82% to 90%.