In the second post, I will try to tackle the problem by using recurrent neural network and attention based LSTM encoder. Further, to make one step closer to implement Hierarchical Attention Networks for Document Classification, I will implement an Attention Network on top of LSTM/GRU for the classification task.
Please note that all exercises are based on Kaggle’s IMDB dataset. And implementation are all based on Keras
Text classification using LSTM
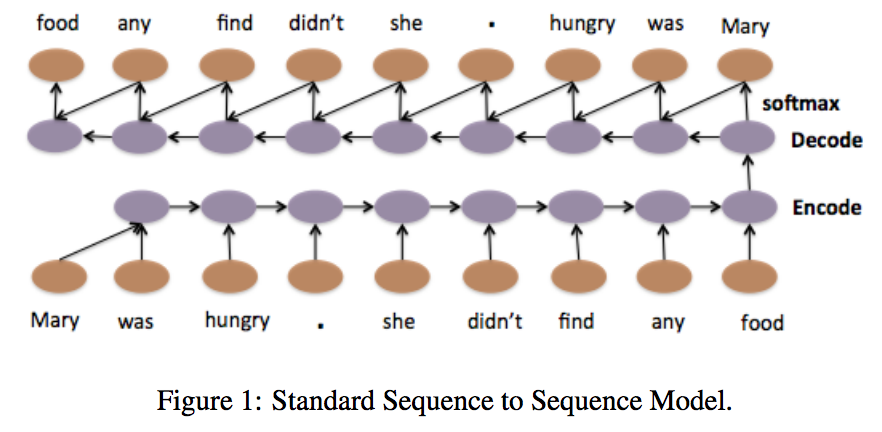
By using LSTM encoder, we intent to encode all information of the text in the last output of recurrent neural network before running feed forward network for classification. This is very similar to neural translation machine and sequence to sequence learning. See the following figure that came from A Hierarchical Neural Autoencoder for Paragraphs and Documents.
 |
I’m going to use LSTM layer in Keras to implement this. Other than forward LSTM, here I am going to use bidirectional LSTM and concatenate both last output of LSTM outputs. Keras has provide a very nice wrapper called bidirectional, which will make this coding exercise effortless. You can see the sample code here
The following code snippet is pretty much the same as Keras sample code except that I didn’t use any drop out layer.
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
l_lstm = Bidirectional(LSTM(100))(embedded_sequences)
preds = Dense(2, activation='softmax')(l_lstm)
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
print("model fitting - Bidirectional LSTM")
model.summary()
model.fit(x_train, y_train, validation_data=(x_val, y_val),
nb_epoch=10, batch_size=50)
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_1 (InputLayer) (None, 1000) 0
____________________________________________________________________________________________________
embedding_1 (Embedding) (None, 1000, 100) 8057000 input_1[0][0]
____________________________________________________________________________________________________
bidirectional_1 (Bidirectional) (None, 200) 160800 embedding_1[0][0]
____________________________________________________________________________________________________
dense_1 (Dense) (None, 2) 402 bidirectional_1[0][0]
====================================================================================================
Total params: 8218202
____________________________________________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 1088s - loss: 0.5343 - acc: 0.7304 - val_loss: 0.3738 - val_acc: 0.8414
Epoch 2/10
20000/20000 [==============================] - 1092s - loss: 0.3348 - acc: 0.8605 - val_loss: 0.3199 - val_acc: 0.8678
Epoch 3/10
20000/20000 [==============================] - 1091s - loss: 0.2382 - acc: 0.9083 - val_loss: 0.2758 - val_acc: 0.8912
Epoch 4/10
20000/20000 [==============================] - 1092s - loss: 0.1808 - acc: 0.9309 - val_loss: 0.2562 - val_acc: 0.8988
Epoch 5/10
20000/20000 [==============================] - 1087s - loss: 0.1383 - acc: 0.9492 - val_loss: 0.2572 - val_acc: 0.9068
Epoch 6/10
20000/20000 [==============================] - 1091s - loss: 0.1032 - acc: 0.9634 - val_loss: 0.2666 - val_acc: 0.9040
Epoch 7/10
20000/20000 [==============================] - 1088s - loss: 0.0736 - acc: 0.9750 - val_loss: 0.3069 - val_acc: 0.9042
Epoch 8/10
20000/20000 [==============================] - 1087s - loss: 0.0488 - acc: 0.9834 - val_loss: 0.3886 - val_acc: 0.8950
Epoch 9/10
20000/20000 [==============================] - 1081s - loss: 0.0328 - acc: 0.9892 - val_loss: 0.3788 - val_acc: 0.8984
Epoch 10/10
20000/20000 [==============================] - 1087s - loss: 0.0197 - acc: 0.9944 - val_loss: 0.5636 - val_acc: 0.8734The best peformance I can see is about 90.4%.
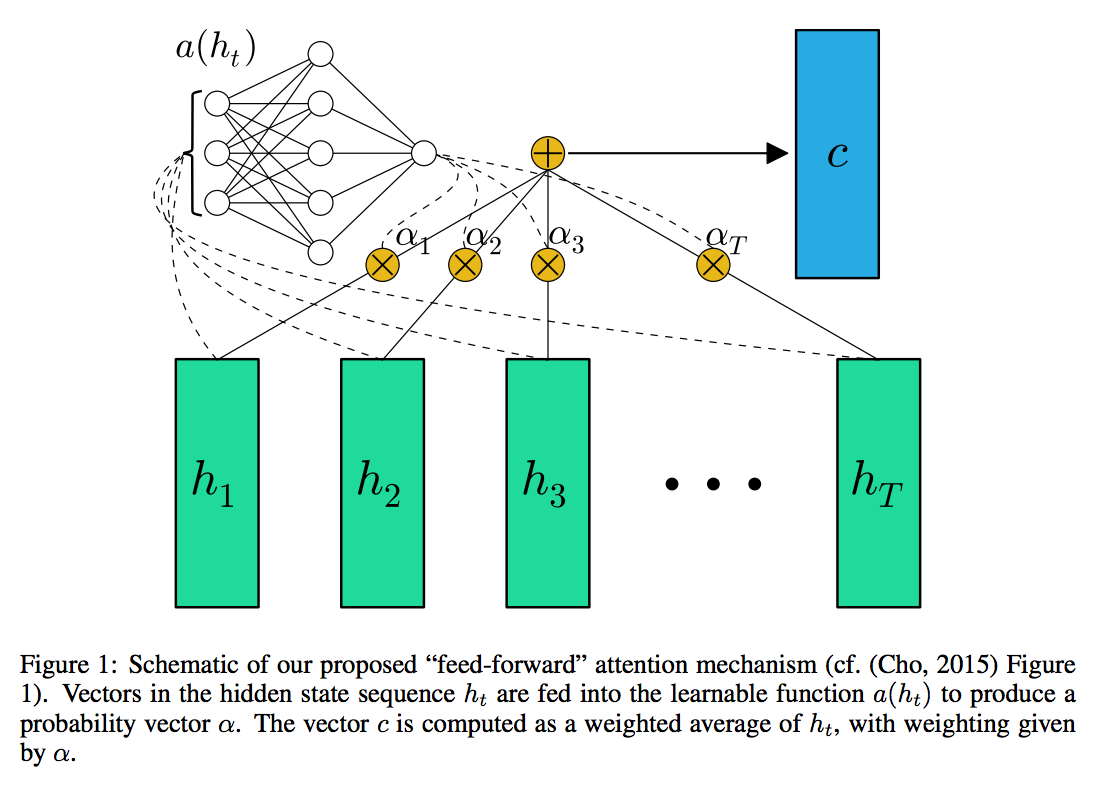
Attention Network
In the following, I am going to implement an attention layer which is well studied in many papers including sequence to sequence learning. Particularly for this text classification task, I have followed the implementation of FEED-FORWARD NETWORKS WITH ATTENTION CAN SOLVE SOME LONG-TERM MEMORY PROBLEMS by Colin Raffel
 |
To implement the attention layer, we need to build a custom Keras layer. You can follow the instruction here
The following code can only strictly run on Theano backend since tensorflow matrix dot product doesn’t behave the same as np.dot. I don’t know how to get a 2D tensor by dot product of 3D tensor of recurrent layer output and 1D tensor of weight.
class AttLayer(Layer):
def __init__(self, **kwargs):
self.init = initializations.get('normal')
#self.input_spec = [InputSpec(ndim=3)]
super(AttLayer, self).__init__(** kwargs)
def build(self, input_shape):
assert len(input_shape)==3
#self.W = self.init((input_shape[-1],1))
self.W = self.init((input_shape[-1],))
#self.input_spec = [InputSpec(shape=input_shape)]
self.trainable_weights = [self.W]
super(AttLayer, self).build(input_shape) # be sure you call this somewhere!
def call(self, x, mask=None):
eij = K.tanh(K.dot(x, self.W))
ai = K.exp(eij)
weights = ai/K.sum(ai, axis=1).dimshuffle(0,'x')
weighted_input = x*weights.dimshuffle(0,1,'x')
return weighted_input.sum(axis=1)
def get_output_shape_for(self, input_shape):
return (input_shape[0], input_shape[-1])Then following code is pretty much the same as the previous one except I will add an attention layer on top of GRU Output
embedding_matrix = np.random.random((len(word_index) + 1, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=True)
sequence_input = Input(shape=(MAX_SEQUENCE_LENGTH,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
l_gru = Bidirectional(GRU(100, return_sequences=True))(embedded_sequences)
l_att = AttLayer()(l_gru)
preds = Dense(2, activation='softmax')(l_att)
model = Model(sequence_input, preds)
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
print("model fitting - attention GRU network")
model.summary()
model.fit(x_train, y_train, validation_data=(x_val, y_val),
nb_epoch=10, batch_size=50)
model fitting - attention GRU network
____________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
====================================================================================================
input_2 (InputLayer) (None, 1000) 0
____________________________________________________________________________________________________
embedding_2 (Embedding) (None, 1000, 100) 8057000 input_2[0][0]
____________________________________________________________________________________________________
bidirectional_2 (Bidirectional) (None, 1000, 200) 120600 embedding_2[0][0]
____________________________________________________________________________________________________
attlayer_1 (AttLayer) (None, 200) 200 bidirectional_2[0][0]
____________________________________________________________________________________________________
dense_2 (Dense) (None, 2) 402 attlayer_1[0][0]
====================================================================================================
Total params: 8178202
____________________________________________________________________________________________________
Train on 20000 samples, validate on 5000 samples
Epoch 1/10
20000/20000 [==============================] - 936s - loss: 0.4635 - acc: 0.7666 - val_loss: 0.3315 - val_acc: 0.8602
Epoch 2/10
20000/20000 [==============================] - 937s - loss: 0.2563 - acc: 0.8980 - val_loss: 0.2848 - val_acc: 0.8824
Epoch 3/10
20000/20000 [==============================] - 933s - loss: 0.1851 - acc: 0.9294 - val_loss: 0.2445 - val_acc: 0.9046
Epoch 4/10
20000/20000 [==============================] - 935s - loss: 0.1322 - acc: 0.9535 - val_loss: 0.2519 - val_acc: 0.9010
Epoch 5/10
20000/20000 [==============================] - 935s - loss: 0.0901 - acc: 0.9687 - val_loss: 0.3053 - val_acc: 0.8922
Epoch 6/10
20000/20000 [==============================] - 937s - loss: 0.0556 - acc: 0.9826 - val_loss: 0.3063 - val_acc: 0.9038
Epoch 7/10
20000/20000 [==============================] - 936s - loss: 0.0317 - acc: 0.9913 - val_loss: 0.4064 - val_acc: 0.8980
Epoch 8/10
20000/20000 [==============================] - 936s - loss: 0.0187 - acc: 0.9946 - val_loss: 0.3858 - val_acc: 0.9012
Epoch 9/10
20000/20000 [==============================] - 934s - loss: 0.0099 - acc: 0.9975 - val_loss: 0.4575 - val_acc: 0.9062
Epoch 10/10
20000/20000 [==============================] - 933s - loss: 0.0046 - acc: 0.9986 - val_loss: 0.5417 - val_acc: 0.9008The accuracy we can achieve is 90.4%
Compare to previous approach, the result is pretty much the same.
To achieve the best performances, we may 1) fine tune hyper parameters 2) further improve text preprocessing. 3) apply drop out layer
Full source code is in my repository in github.
Conclusion
Based on the observations, performances of both approaches are quite good. Long sentence sequence trainings are quite slow, in both approaches, training time took more than 15 minutes for each epoch.